오픈소스 프레임워크 정리(Spark, Oozie, Kafka, Storm)
하둡의 한계:
맵리듀스 잡의 결과를 다른 잡에서 사용하려면 이 결과를 HDFS에 저장해야 하기 때문에 이전 잡의 결과가 다음 잡의 입력이 되는 반복 알고리즘에는 맞지 않다.
하둡은 low-level 프레임워크다보니 데이터를 조작하는 high-level 프레임워크나 도구가 많아 환경이 복잡해졌다.
Spark
특징
빅데이터 처리를 위해 대량의 데이터를 고속 처리하는 오픈소스 병렬 분산 처리 플랫폼이다.
데이터셋을 추상적으로 다루기 위한 RDD라는 데이터셋이 있다.
RDD(Resilient Distributed Dataset)은 노드에 장애가 발생해도 데이터셋을 재구성할 수 있는 복원성을 갖는다.
배치 처리, 스트림 처리, SQL 처리와 같은 서로 다른 형태의 애플리케이션을 하나의 환경에서 통합적으로 다룰 수 있다.
HDFS만 읽는 것이 아니라 Hive, Hbase, PostgreSQL, Mysql, Maria, CSV 등의 DB도 읽을 수 있다.
스톰보다는 범용 분산형 컴퓨팅 플랫폼에 가깝다.
하둡에서 맵리듀스의 기능성을 대체할 수 있고 자원 스케줄링에는 얀을 이용한다.
하둡과 같이 사용하지 않을 경우 NFS, AFS 등 네트워크/분산형 파일 시스템을 이용해야 클러스터에서 실행시킬 수 있다. 그래야만 각 노드가 기반이 되는 데이터에 접속할 수 있기 때문이다.
구조
스파크 코어: 병렬분산처리 엔진
스파크 SQL: SQL 담당
스파크 스트리밍: 스트림 처리 담당
MLlib: 머신 러닝 담당
그래프X: 그래프 처리 담당
장점
메모리 효율을 높여서 하둡의 맵리듀스보다 빠르게 설계되었다.
맵리듀스처럼 잡에 필요한 데이터를 디스크에 매번 가져오는 대신 데이터를 메모리에 캐시로 저장하는 인메모리 실행 모델을 쓴다.
이런 변화는 머신 러닝, 그래프 알고리즘 등 반복 알고리즘에 유리하다.
맵리듀스는 기본적으로 메인, 매퍼, 리듀스 클래스 세 가지를 만들어야 하지만 스파크는 간단한 코드로 짤 수 있다.
일괄 처리 작업이나 데이터 마이닝 같은 온라인 분석 처리(Online Analytical Processing)에 유용하다.
단점
데이터 셋이 적어서 단일 노드로 충분한 애플리케이션에서는 스파크가 분산 아키텍쳐로 인해 오히려 성능이 떨어진다.
스파크는 온라인 트랜잭션 처리를 염두에 두지 않고 설계되었기 때문에 대량의 트랜잭션을 빨리 처리해야 하는 애플리케이션에는 유용하지 않다.
하둡은 중간 결과물을 계속 디스크에 저장하기 때문에 fault tolerance가 비교적 좋다.
인메모리 기반 프레임워크다보니 높은 메모리가 필요하다.
사용사례
대용량의 데이터로부터 특정 컬럼이나 조건에 맞는 레코드들만 추출하고 해당 레코드를 반복해서 변환처리한 뒤 최종 집계하는 처리에 쓰인다.
단, 반복 실행되는 처리가 메모리 용량을 넘지 않아야한다.
Storm
특징
확장성이 아주 크고, 빠르며, 내결함성이 강한 분산형 스트리밍 프로세싱 연산 프레임워크이다.
하둡에서 실시간으로 데이터 스트림을 처리할 수 있다.
사용자가 만든 spout와 bolt를 사용하여 정보원과 조작부를 정의함으로써 스트리밍 데이터의 일괄, 분산 처리를 가능하게 한다.
정상적으로 처리되지 않은 데이터를 재생하는 기능을 통해 데이터 처리를 보장할 수 있다.
Spout은 데이터를 토폴로지로 가져온다. 하나 이상의 스트림을 토폴로지에 보낸다.
Bolt는 Spout 또는 다른 Bolt에서 내보낸 스트림을 사용하는데 필요에 따라 스트림을 토폴로지로 내보낼 수 있다. HDFS, Kafka, 또는 HBase와 같은 외부 서비스에 데이터를 쓰는 역할을 수행한다.
튜플: 실시간으로 생성되어 전달되는 데이터 구조체이다. CSV(Comma Seperated Values)로 구상되었다.
스파우트가 이 튜플을 생길 때마다 처리하는 곳으로 보내준다.
볼트가 튜플들의 스트림을 받아 처리하여 유의미한 자료를 만들어낸다.
즉, 토폴로지가 실행되면 스파우트가 기존 프로그램에서 실시간으로 생성되는 데이터를 가지고 계속해서 튜플을 만들어 볼트에게 던지면 볼트는 이것을 계속 처리하여 실시간으로 원하는 결과를 만들어낸다.
클로저 언어를 사용하지만 스파웃과 볼트를 DAG 토폴로지로 지원한다.
스톰 자체는 클로저에 기반을 두고 있지만 JVM에서 실행된다.
볼트는 사실상 모든 언어로 개발이 가능하다.
구조
장점
모든 형태의 소스로부터 데이터를 수신할 수 있는 풍부한 스파웃이 있다.
필요에 따라 스톰과 하둡을 쉽게 호환시킬 수 있는 어댑터가 있다.
단점
사용사례
데이터 스트림의 실시간 롤링 매트릭스 계산, 증진적 계산, 이벤트 처리에 우수하다.
Oozie
특징
하둡에서 사용하는 자바 기반 워크플로우 스케줄러 프레임워크이다.
프로젝트의 규모가 커지면서 여러 개의 맵리듀스 잡을 서로 연결해 사용하는 것이 불가피해져서 우지가 필요해졌다.
우지가 각각 잡들의 시작과 종결, 그 사이의 각종 분기 조건 등을 지정해 스케줄링한다.
액션: 우지에서 실행할 수 있는 하나의 작업 단위이다. 맵리듀스작업, 스파크작업 등.
워크플로우: 액션들의 제어와 의존관계를 DAG로 표현한다. 하나의 워크플로우는 여러 개의 액션을 포함한다.
Coordinator: 데이터셋과 워크플로우를 실행하는 스케쥴을 정의한다.
Bundle: coordinator의 모임이다.
워크플로우는 컨트롤 노드와 액션 노드 두 가지로 구성된다.
컨트롤노드는 작업의 시작과 끝을 지정하기도(start node, end node) 하고 진행 경로를 통제하기도 한다(decision node, fork node, join node).
액션 노드는 하나의 워크플로우가 실제 수행 작업을 처리하도록 한다.
Scheduling: 특정 시간에 액션을 수행한다.
Coordinating: 이전 액션이 성공적으로 끝나면 다음 액션을 시작한다.
Managing: 액션 성공 여부를 메일로 보낸다. 액션에 대한 정보를 저장한다.
클라이언트는 우지 서버에 연결해서 job properties를 제출한다.
우지 서버가 HDFS로부터 workflow 파일을 읽는다.
우지 서버에서 workflow를 파싱해서 액션을 수행한다.
기본적으로 아파치의 Derby 데이터베이스가 내장돼있고 필요에 따라 외부 데이터베이스를 이용할 수 있다.
구조
Workflow Engine: 워크플로우를 실행한다. 워크플로우를 정의하거나 정의된 내용에 따라 실제 작업이 진행되도록 한다.
Coordinator(Scheduler): 미리 지정된 우지의 데이터셋의 존재 여부나 frequency에 따라 워크플로우를 스케쥴링한다.
REST API: 실행, 스케줄, 워크플로우 모니터링하는 API가 있다.
CLI: CLI를 통해서 작업을 실행하거나 스케줄링, 모니터링이 가능하다.
Bundle: 코디네이터를 모아서 한번에 제어하게 해주는 단위이다.
Notification: 작업 상태가 변경 여부에 따라 이벤트를 보내준다.
SLA(Service Level Agreement) monitoring: 시작, 종료 시간이나 지속 시간을 기반으로 하여 작업에 대한 SLA를 추적하는데 어떤 작업이 SLA를 달성하거나 못하는지 체크해서 사용자에게 알려준다.
Database: 코디네이터, 번들 SLA 및 workflow 이력 등을 저장한다.
장점
단점
사용사례
Kafka
특징
데이터 파이프라인을 만들 때 주로 사용되는 오픈소스 프레임워크이다.
대용량의 실시간 로그 처리에 특화되어 있다.
메세지 큐의 일종이다.
메시지를 메모리에 저장했던 기존 메시징 시스템과 달리 파일 시스템에 저장함으로써 메세지 유실 위험을 줄였다.
크게 producer, consumer, broker로 구성된다.
주키퍼가 카프카의 상태와 클러스터를 관리해주고 카프카 클러스터의 리더를 발탁하는 방식도 주키퍼가 제공한다.
publisher subscriber 모델: 데이터 큐를 중간에 두고 서로 독립적으로 데이터를 생산하고 소비한다. publisher는 메세지를 수신자에게 직접 보내주는 게 아니라 메세지를 topic에 따라 분류하고, 수신자는 구독하고 있는 topic에 대한 메세지를 읽어온다.
HA 및 Scalability: 카프카는 클러스터로 작동하므로 fault-tolerant한 고가용성 서비스를 제공할 수 있고 scale-out이 가능하다.
Sequential Store and Process in Disk: 메세지를 메모리 큐에 적재하는 것이 아니라 디스크에 순차적으로 저장한다. 이로써 서버 장애가 나도 유실 걱정이 없고, 순차적으로 저장돼있으니까 디스크 I/O가 줄어 성능이 빨라진다.
Distributed Processing: 파티션이란 개념을 도입해서 여러 개의 파티션을 서버들에 분산시키고 상황에 맞추어 빠르게 처리한다.
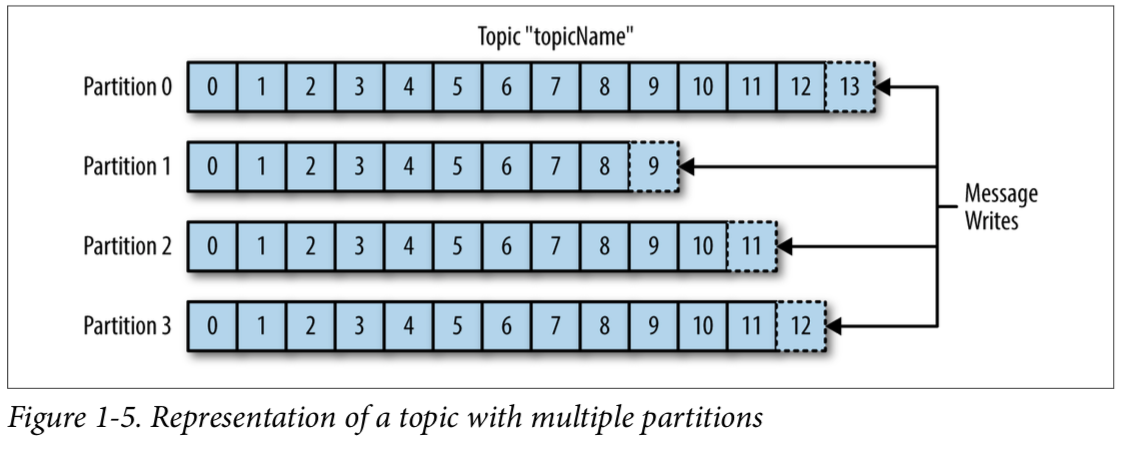
토픽: 카프카 클러스터에 데이터를 관리할 때 그 기준이 되는 개념이다. 어떤 데이터를 관리하는 하나의 그룹이다. 하나의 토픽은 한 개 이상의 파티션으로 구성되어 있다.
파티션: 각 토픽 당 데이터를 분산 처리하는 단위이다. 토픽 안에 파티션을 나눠서 그 수대로 데이터를 분산처리한다. 설정한 replica의 수 만큼 파티션이 각 서버들에 복제된다. 운영 중에 파티션의 수를 늘릴 수는 있지만 줄일 수는 없다. 여러 개의 파티션을 가짐으로써 분산 처리가 가능하다. 100번의 append 작업이 일어나야할 때 파티션이 5개라면 병렬도 대략 20번의 작업 시간이 소요된다.
리더, 팔로워: 각 파티션 당 복제된 파티션 중 하나의 리더가 선출된다. 리더에서 읽기 쓰기 연산이 이루어지고 나머지 팔로워에서는 리더의 데이터를 복사 하는 역할만 한다.
파티션이 4개고 그 토픽을 subscribe하는 컨슈머가 3개면 컨슈머 하나가 두 개의 파티션을 소비한다.
파티션2개 컨슈머 3개면 하나의 컨슈머는 아무것도 하지 않는다.
따라서 파티션 수를 정할 땐 컨슈머 수도 고려해야한다.
구조
broker: 토픽을 기준으로 메세지를 관리한다. 카프카 서버이다.
producer: 특정 토픽의 메시지를 생성한 뒤 해당 메시지를 카프카 클러스터에 전달한다.
consumer: 구독하고 있는 토픽에 맞는 브로커를 찾아서 메시지를 가져간 뒤 처리한다. 자신이 가져와야하는 토픽 안의 파티션의 데이터를 pull하게 되고 컨슈머 그룹 안의 컨슈머들이 파티션이 나눠져 있는 만큼 데이터를 분산처리한다.
장점
broker가 consumer에게 메시지를 푸쉬하던 기존 시스템과 달리 consumer가 broker로부터 처리할 수 있는 만큼만 직접 pull해오기 때문에 최적의 성능을 낼 수 있다.
기존 메시징 시스템 ActiveMQ, RabbitMQ와의 차이점
TPS가 우수하고 분산 시스템에 적용하기 좋다.
단순한 메시지 헤더를 지닌 TCP 기반의 프로토콜을 사용함으로써 프로토콜에 의한 오버헤드를 감소시켰다.
다수의 메시지를 batch 형태로 broker에 한꺼번에 전달할 수 있어 TCP/IP 라운드트립 횟수를 줄일 수 있었다.
메시지를 파일 시스템에 저장해서 안전하다.
단점
사용사례

<https://engkimbs.tistory.com/691>
<https://medium.com/@umanking/%EC%B9%B4%ED%94%84%EC%B9%B4%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0-%ED%95%98%EA%B8%B0%EC%A0%84%EC%97%90-%EB%A8%BC%EC%A0%80-data%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0%ED%95%B4%EB%B3%B4%EC%9E%90-d2e3ca2f3c2>
맵리듀스 잡의 결과를 다른 잡에서 사용하려면 이 결과를 HDFS에 저장해야 하기 때문에 이전 잡의 결과가 다음 잡의 입력이 되는 반복 알고리즘에는 맞지 않다.
하둡은 low-level 프레임워크다보니 데이터를 조작하는 high-level 프레임워크나 도구가 많아 환경이 복잡해졌다.
Spark
특징
빅데이터 처리를 위해 대량의 데이터를 고속 처리하는 오픈소스 병렬 분산 처리 플랫폼이다.
데이터셋을 추상적으로 다루기 위한 RDD라는 데이터셋이 있다.
RDD(Resilient Distributed Dataset)은 노드에 장애가 발생해도 데이터셋을 재구성할 수 있는 복원성을 갖는다.
배치 처리, 스트림 처리, SQL 처리와 같은 서로 다른 형태의 애플리케이션을 하나의 환경에서 통합적으로 다룰 수 있다.
HDFS만 읽는 것이 아니라 Hive, Hbase, PostgreSQL, Mysql, Maria, CSV 등의 DB도 읽을 수 있다.
스톰보다는 범용 분산형 컴퓨팅 플랫폼에 가깝다.
하둡에서 맵리듀스의 기능성을 대체할 수 있고 자원 스케줄링에는 얀을 이용한다.
하둡과 같이 사용하지 않을 경우 NFS, AFS 등 네트워크/분산형 파일 시스템을 이용해야 클러스터에서 실행시킬 수 있다. 그래야만 각 노드가 기반이 되는 데이터에 접속할 수 있기 때문이다.
구조
스파크 코어: 병렬분산처리 엔진
스파크 SQL: SQL 담당
스파크 스트리밍: 스트림 처리 담당
MLlib: 머신 러닝 담당
그래프X: 그래프 처리 담당
장점
메모리 효율을 높여서 하둡의 맵리듀스보다 빠르게 설계되었다.
맵리듀스처럼 잡에 필요한 데이터를 디스크에 매번 가져오는 대신 데이터를 메모리에 캐시로 저장하는 인메모리 실행 모델을 쓴다.
이런 변화는 머신 러닝, 그래프 알고리즘 등 반복 알고리즘에 유리하다.
맵리듀스는 기본적으로 메인, 매퍼, 리듀스 클래스 세 가지를 만들어야 하지만 스파크는 간단한 코드로 짤 수 있다.
일괄 처리 작업이나 데이터 마이닝 같은 온라인 분석 처리(Online Analytical Processing)에 유용하다.
단점
데이터 셋이 적어서 단일 노드로 충분한 애플리케이션에서는 스파크가 분산 아키텍쳐로 인해 오히려 성능이 떨어진다.
스파크는 온라인 트랜잭션 처리를 염두에 두지 않고 설계되었기 때문에 대량의 트랜잭션을 빨리 처리해야 하는 애플리케이션에는 유용하지 않다.
하둡은 중간 결과물을 계속 디스크에 저장하기 때문에 fault tolerance가 비교적 좋다.
인메모리 기반 프레임워크다보니 높은 메모리가 필요하다.
사용사례
대용량의 데이터로부터 특정 컬럼이나 조건에 맞는 레코드들만 추출하고 해당 레코드를 반복해서 변환처리한 뒤 최종 집계하는 처리에 쓰인다.
단, 반복 실행되는 처리가 메모리 용량을 넘지 않아야한다.
Storm
특징
확장성이 아주 크고, 빠르며, 내결함성이 강한 분산형 스트리밍 프로세싱 연산 프레임워크이다.
하둡에서 실시간으로 데이터 스트림을 처리할 수 있다.
사용자가 만든 spout와 bolt를 사용하여 정보원과 조작부를 정의함으로써 스트리밍 데이터의 일괄, 분산 처리를 가능하게 한다.
정상적으로 처리되지 않은 데이터를 재생하는 기능을 통해 데이터 처리를 보장할 수 있다.
Spout은 데이터를 토폴로지로 가져온다. 하나 이상의 스트림을 토폴로지에 보낸다.
Bolt는 Spout 또는 다른 Bolt에서 내보낸 스트림을 사용하는데 필요에 따라 스트림을 토폴로지로 내보낼 수 있다. HDFS, Kafka, 또는 HBase와 같은 외부 서비스에 데이터를 쓰는 역할을 수행한다.
튜플: 실시간으로 생성되어 전달되는 데이터 구조체이다. CSV(Comma Seperated Values)로 구상되었다.
스파우트가 이 튜플을 생길 때마다 처리하는 곳으로 보내준다.
볼트가 튜플들의 스트림을 받아 처리하여 유의미한 자료를 만들어낸다.
즉, 토폴로지가 실행되면 스파우트가 기존 프로그램에서 실시간으로 생성되는 데이터를 가지고 계속해서 튜플을 만들어 볼트에게 던지면 볼트는 이것을 계속 처리하여 실시간으로 원하는 결과를 만들어낸다.
클로저 언어를 사용하지만 스파웃과 볼트를 DAG 토폴로지로 지원한다.
스톰 자체는 클로저에 기반을 두고 있지만 JVM에서 실행된다.
볼트는 사실상 모든 언어로 개발이 가능하다.
구조
장점
모든 형태의 소스로부터 데이터를 수신할 수 있는 풍부한 스파웃이 있다.
필요에 따라 스톰과 하둡을 쉽게 호환시킬 수 있는 어댑터가 있다.
단점
사용사례
데이터 스트림의 실시간 롤링 매트릭스 계산, 증진적 계산, 이벤트 처리에 우수하다.
Oozie
특징
하둡에서 사용하는 자바 기반 워크플로우 스케줄러 프레임워크이다.
프로젝트의 규모가 커지면서 여러 개의 맵리듀스 잡을 서로 연결해 사용하는 것이 불가피해져서 우지가 필요해졌다.
우지가 각각 잡들의 시작과 종결, 그 사이의 각종 분기 조건 등을 지정해 스케줄링한다.
액션: 우지에서 실행할 수 있는 하나의 작업 단위이다. 맵리듀스작업, 스파크작업 등.
워크플로우: 액션들의 제어와 의존관계를 DAG로 표현한다. 하나의 워크플로우는 여러 개의 액션을 포함한다.
Coordinator: 데이터셋과 워크플로우를 실행하는 스케쥴을 정의한다.
Bundle: coordinator의 모임이다.
워크플로우는 컨트롤 노드와 액션 노드 두 가지로 구성된다.
컨트롤노드는 작업의 시작과 끝을 지정하기도(start node, end node) 하고 진행 경로를 통제하기도 한다(decision node, fork node, join node).
액션 노드는 하나의 워크플로우가 실제 수행 작업을 처리하도록 한다.
Scheduling: 특정 시간에 액션을 수행한다.
Coordinating: 이전 액션이 성공적으로 끝나면 다음 액션을 시작한다.
Managing: 액션 성공 여부를 메일로 보낸다. 액션에 대한 정보를 저장한다.
클라이언트는 우지 서버에 연결해서 job properties를 제출한다.
우지 서버가 HDFS로부터 workflow 파일을 읽는다.
우지 서버에서 workflow를 파싱해서 액션을 수행한다.
기본적으로 아파치의 Derby 데이터베이스가 내장돼있고 필요에 따라 외부 데이터베이스를 이용할 수 있다.
구조
Workflow Engine: 워크플로우를 실행한다. 워크플로우를 정의하거나 정의된 내용에 따라 실제 작업이 진행되도록 한다.
Coordinator(Scheduler): 미리 지정된 우지의 데이터셋의 존재 여부나 frequency에 따라 워크플로우를 스케쥴링한다.
REST API: 실행, 스케줄, 워크플로우 모니터링하는 API가 있다.
CLI: CLI를 통해서 작업을 실행하거나 스케줄링, 모니터링이 가능하다.
Bundle: 코디네이터를 모아서 한번에 제어하게 해주는 단위이다.
Notification: 작업 상태가 변경 여부에 따라 이벤트를 보내준다.
SLA(Service Level Agreement) monitoring: 시작, 종료 시간이나 지속 시간을 기반으로 하여 작업에 대한 SLA를 추적하는데 어떤 작업이 SLA를 달성하거나 못하는지 체크해서 사용자에게 알려준다.
Database: 코디네이터, 번들 SLA 및 workflow 이력 등을 저장한다.
장점
단점
사용사례
Kafka
특징
데이터 파이프라인을 만들 때 주로 사용되는 오픈소스 프레임워크이다.
대용량의 실시간 로그 처리에 특화되어 있다.
메세지 큐의 일종이다.
메시지를 메모리에 저장했던 기존 메시징 시스템과 달리 파일 시스템에 저장함으로써 메세지 유실 위험을 줄였다.
크게 producer, consumer, broker로 구성된다.
주키퍼가 카프카의 상태와 클러스터를 관리해주고 카프카 클러스터의 리더를 발탁하는 방식도 주키퍼가 제공한다.
publisher subscriber 모델: 데이터 큐를 중간에 두고 서로 독립적으로 데이터를 생산하고 소비한다. publisher는 메세지를 수신자에게 직접 보내주는 게 아니라 메세지를 topic에 따라 분류하고, 수신자는 구독하고 있는 topic에 대한 메세지를 읽어온다.
HA 및 Scalability: 카프카는 클러스터로 작동하므로 fault-tolerant한 고가용성 서비스를 제공할 수 있고 scale-out이 가능하다.
Sequential Store and Process in Disk: 메세지를 메모리 큐에 적재하는 것이 아니라 디스크에 순차적으로 저장한다. 이로써 서버 장애가 나도 유실 걱정이 없고, 순차적으로 저장돼있으니까 디스크 I/O가 줄어 성능이 빨라진다.
Distributed Processing: 파티션이란 개념을 도입해서 여러 개의 파티션을 서버들에 분산시키고 상황에 맞추어 빠르게 처리한다.
토픽: 카프카 클러스터에 데이터를 관리할 때 그 기준이 되는 개념이다. 어떤 데이터를 관리하는 하나의 그룹이다. 하나의 토픽은 한 개 이상의 파티션으로 구성되어 있다.
파티션: 각 토픽 당 데이터를 분산 처리하는 단위이다. 토픽 안에 파티션을 나눠서 그 수대로 데이터를 분산처리한다. 설정한 replica의 수 만큼 파티션이 각 서버들에 복제된다. 운영 중에 파티션의 수를 늘릴 수는 있지만 줄일 수는 없다. 여러 개의 파티션을 가짐으로써 분산 처리가 가능하다. 100번의 append 작업이 일어나야할 때 파티션이 5개라면 병렬도 대략 20번의 작업 시간이 소요된다.
리더, 팔로워: 각 파티션 당 복제된 파티션 중 하나의 리더가 선출된다. 리더에서 읽기 쓰기 연산이 이루어지고 나머지 팔로워에서는 리더의 데이터를 복사 하는 역할만 한다.
파티션이 4개고 그 토픽을 subscribe하는 컨슈머가 3개면 컨슈머 하나가 두 개의 파티션을 소비한다.
파티션2개 컨슈머 3개면 하나의 컨슈머는 아무것도 하지 않는다.
따라서 파티션 수를 정할 땐 컨슈머 수도 고려해야한다.
구조
broker: 토픽을 기준으로 메세지를 관리한다. 카프카 서버이다.
producer: 특정 토픽의 메시지를 생성한 뒤 해당 메시지를 카프카 클러스터에 전달한다.
consumer: 구독하고 있는 토픽에 맞는 브로커를 찾아서 메시지를 가져간 뒤 처리한다. 자신이 가져와야하는 토픽 안의 파티션의 데이터를 pull하게 되고 컨슈머 그룹 안의 컨슈머들이 파티션이 나눠져 있는 만큼 데이터를 분산처리한다.
장점
broker가 consumer에게 메시지를 푸쉬하던 기존 시스템과 달리 consumer가 broker로부터 처리할 수 있는 만큼만 직접 pull해오기 때문에 최적의 성능을 낼 수 있다.
기존 메시징 시스템 ActiveMQ, RabbitMQ와의 차이점
TPS가 우수하고 분산 시스템에 적용하기 좋다.
단순한 메시지 헤더를 지닌 TCP 기반의 프로토콜을 사용함으로써 프로토콜에 의한 오버헤드를 감소시켰다.
다수의 메시지를 batch 형태로 broker에 한꺼번에 전달할 수 있어 TCP/IP 라운드트립 횟수를 줄일 수 있었다.
메시지를 파일 시스템에 저장해서 안전하다.
단점
사용사례
<https://engkimbs.tistory.com/691>
<https://medium.com/@umanking/%EC%B9%B4%ED%94%84%EC%B9%B4%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0-%ED%95%98%EA%B8%B0%EC%A0%84%EC%97%90-%EB%A8%BC%EC%A0%80-data%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C-%EC%9D%B4%EC%95%BC%EA%B8%B0%ED%95%B4%EB%B3%B4%EC%9E%90-d2e3ca2f3c2>

댓글
댓글 쓰기