오픈소스 프레임워크 정리(Ambari, Zookeeper, Hive, HBase)
Ambari
특징
하둡 클러스터를 관리하는 웹 기반 관리 툴이다.
하둡 클러스터의 상태를 모니터링해서 대쉬보드에 보여준다.
암바리를 이용해서 서비스를 시작이나 중지 시킬 수 있고 클러스터에 호스트를 추가할 수 있고 서비스 설정을 업데이트 할 수 있다.
Kerberos 기반의 하둡 클러스터를 설치함으로써 authentication, authorization, auditing 등을 제공한다.
호스트에 하둡 서비스를 설치하는 것을 도와준다.
각 호스트는 암바리 에이전트의 복사본을 갖고 있어서 암바리 서버의 통제를 받을 수 있다.
아파치 애플리케이션에 단순히 뷰를 추가함으로써 기능성을 확장할 수 있다.
active directory에서 LDAP과 sync할 수 있다.
써드파티 업체들이 쉽게 암바리에 기능을 추가할 수 있도록 stack이나 view의 기능을 제공한다.
구조
암바리 서버: 관리하는 모든 동작들이 들어오는 곳이다. ambari-server.py라는 파이썬 코드에 의해 동작한다.
암바리 에이전트: 암바리로 관리하고 싶은 모든 노드들에 있다. 하트비트를 마스터로 보낸다. 이 에이전트를 통해서 서버는 여러 작업들을 한다.
암바리 스택: 암바리가 제공하는 설치/배포 기능에 다른 eco들도 쉽게 추가할 수 있도록 한다.
암바리 뷰: 새로 개발된 기능의 UI를 쉽게 추가할 수 있도록 API를 지원한다. 암바리 컨테이너 안에 넣을 수 있는 애플리케이션과 같은 것이다. 자바로 쓰여있는 server-side resource는 외부 시스템과 integrate할 수 있다. HTML, JavaScript와 같은 client-side assets는 암바리 웹에서 보여지는 것을 제공한다.
장점
하둡 클러스터를 설치, 설정, 관리하기 쉽다.
보안이나 애플리케이션 관리를 중앙화한다.
단점
사용사례
Zookeeper
특징
분산 코디네이션 서비스 시스템으로서 분산 시스템 내에서 중요한 상태 정보나 설정 정보등을 유지한다.
분산 코디네이션 시스템을 제대로 작성하지 못할 경우 SPOF가 생기거나 race condition이 생길 수 있다.
분산 시스템을 코디네이션 하는 용도이기 때문에 데이터 접근이 빨라야 하고 장애에 대한 대응 능력이 있어야 한다.
따라서 자체적으로 클러스터링을 제공하며 장애가 일어나도 데이터 유실 없이 fail over/fail back이 가능하다.
디렉토리 구조 기반으로 znode라는 데이터 저장 객체를 제공한다.
Configuration Management: 클러스터의 설정 정보를 최신으로 유지한다.
Cluster Management: 클러스터 내에 서버의 변화가 생겼을 때 다른 서버에서도 알 수 있도록 한다.
Leader Selection: 대표 노드를 고른다. 복제된 여러 노드 중 연산이 일어날 노드를 선택한다.
Locking and Synchronization System: Data condition을 예방한다.
특정 서버에 쓰기 동작을 할 경우 클라이언트가 서버에 접속해서 데이터를 업데이트하고 그 서버는 주키퍼 서버에 업데이트 내용을 알린다. 그러면 그 leader 서버(주키퍼 서버)는 broadcast형식으로 follower 주키퍼 서버들에게 보내서 전체 서버 데이터들이 일관된 상태로 유지되도록 한다.
주키퍼 클라이언트가 특정 노드에 와치를 걸어 놓으면 해당 노드가 변경 됐을 때 클라이언트로 callback호출을 날려주고 watcher는 삭제된다.
하나의 서버만 서비스를 수행하지 않고 알맞게 분산하여 각각의 클라이언트들에게 부하가 분산되도록 한다.
하나의 서버에서 처리된 결과가 다른 서버들에 동기화된다.
액티브 서버가 무너질 경우 스탠바이 서버가 액티브 서버로 바뀌어 failover/failback을 한다.
각각 서버들의 환경설정을 주키퍼 자체적으로 관리한다.
앙상블 안의 주키퍼 서버들은 조율된 상태이며 항상 같은 데이터를 갖고 있는다.
클라이언트는 앙상블의 어떤 서버에 접근해서 데이터를 읽거나 업데이트한다.
Leader가 아닌 follower 서버에 write작업이 일어나면 그 follower 서버는 leader 서버에게 업데이트 된 내용을 알려주고 그 leader 서버는 앙상블 내의 모든 follower 서버들에게 broadcast한다.
구조
각각 클라이언트를 갖고 있는 서버들을 묶어서 관리하는데 그중에서 리더 서버가 하나 있다.
앙상블(Ensemble): 여러 주키퍼 서버로 이루어졌다.
Quorum(쿼럼): 앙상블 데이터의 불일치를 방지한다.
앙상블을 이루고 있는 서버들 중에서 과반수 이상의 그룹을 묶은 뒤 쿼럼이라 한다.
예상치 못한 장애가 발생해도 시스템의 일관성을 유지하기 위함이다.
쿼럼이 과반수 이상이 아닐 때는 쿼럼의 서버들이 다운돼도 나머지들 중에서 또 쿼럼을 만들 수 있기 때문에 주키퍼가 유지된다. 유지되면 안되는데.
쿼럼이 과반수 이상일 때는 쿼럼의 서버들이 모두 다운되면 나머지들은 과반수 이하이므로 그것들로 쿼럼을 구성할 수 없기 때문에 주키퍼를 이용불가 상태로 만들어준다.
Znode: 분산 데이터 시스템.
Znode의 stat 구조에는 znode의 메타데이터가 있다.
version number: 모든 znode는 버전 넘버가 있어서 업데이트 될 때마다 이 값도 업데이트 된다.
ACL(Action Control List): 권한 획득 메커니즘이다. 이걸 통해서 노드에 접근할 수 있다.
Timestamp: Znode가 만들어진 시간과 업데이트 된 시간이 기록된다.
Data length: 데이터의 크기이다.
Znode는 세 가지 종류가 있다. Persistence znode, Ephemeral znode(leader selection에 쓰임), Sequential znode(lock에 쓰임).
장점
개발자가 코디네이션 로직보다는 비즈니스 핵심 로직에 집중하게끔 도와준다.
단점
사용사례
단순히 디렉토리 형태의 데이터 저장소이지만 다양한 시나리오에 사용될 수 있다.
와쳐와 sequence node를 이용하면 큐를 구현할 수 있다.
분산 서버가 공유 자원을 접근하려고 했을 때 특정 작업에 lock을 걸고 작업을 할 수 있는 기능을 구현할 수 있다.
Ephemeral node는 주키퍼 클라이언틀가 살아있을 때만 유효하므로 클러스터 서버들이 ephemeral node를 갖도록 하면 클러스터 내의 살아있는 서버들의 리스트를 갖고 있을 수 있다. 이와 비슷하게 leader 서버가 죽으면 다른 leader 서버를 선출하는 로직을 구현할 수도 있다.

<https://engkimbs.tistory.com/660>
Hive
특징
하둡에서 동작하는 데이터 웨어하우징 프레임워크로서 대용량 데이터 집합들을 모델링하고 프로세싱한다.
HiveQL이라고 불리는 언어를 제공하며 맵리듀스의 모든 기능을 지원한다.
맵리듀스의 상위 언어인데 피그와 다르게 절차적 언어를 사용하지 않고 SQL과 같은 쿼리를 날려서 맵리듀스를 동작시킨다. 정형화된 데이터만 처리할 수 있다.(하이브나 피그 없으면 맵리듀스 사용 못하는건가?)
HDFS의 데이터에 대해서 Meta Store에 저장된 스키마를 기준으로 데이터를 MR, Spark등의 기타 분산 엔진등을 통해 처리하고 이를 사용자에게 정형화된 결과로 제공하는 툴이다.
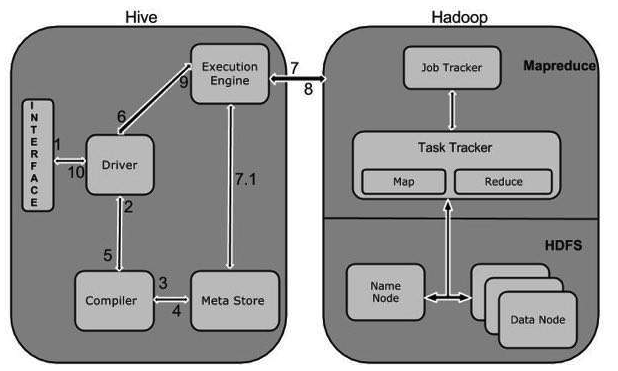
UI로 드라이버에 쿼리를 보낸다. 드라이버는 컴파일러에게 플랜을 요청한다. 컴파일러는 메타스토어에서 메타데이터를 불러온 뒤 플랜을 짜서 드라이버에 보낸다. 드라이버는 받은 플랜을 엑시큐션 엔진에 보낸다. execution engine은 잡을 하둡의 리소스매니저로 보낸다. 리소스매니저는 잡을 완료해서 execution engine으로 보낸다...?
사용자가 하이브웹이나 커맨드라인을 통해서 쿼리를 날린다. 드라이버는 컴파일러에게 쿼리 플랜을 요청하면 컴파일러는 쿼리 플랜을 작성한다. 컴파일러는 메타스토어로부터 쿼리를 처리하는데 필요한 메타정보를 받는다. 컴파일러는 쿼리 플랜을 작성해서 다시 드라이버에게 전달한다. 드라이버는 execution engine에게 쿼리 플랜을 전달한다. execution engine은 네임노드에 있는 잡트래커에게 잡을 전달하고 잡트래커는 태스크트래커에 잡을 임명한다.execution engine은 맵리듀스의 결과를 데이터노드로부터 받고 드라이버에게 그 결과들을 전달한다. 드라이버는 하이브 인터페이스에게 결과들을 전달한다.
기본적으로는 메타데이터를 내장된 아파치 Derby 데이터베이스에 저장하지만 다른 데이터베이스를 사용할 수도 있다.
Schema on Read이다. Table에 insert할 때 테이블 속성과 달라도 에러를 내지 않는다. 스키마온리드이기 때문에 테이블 스키마를 잘 생성해야 데이터를 의도에 맞게 read할 수 있다. 스키마온롸이트는 읽기가 빠르고 스키마온리드는 로드가 빠르다.
구조
하이브의 클라이언트는 CLI, Hive Server, Web Interface로 구성된다.
UI:
CLI, Beeline, JDBC 등.
Metastore:
하이브가 구동될 때 필요한 테이블의 스키마 구조나 다양한 설정값들이 저장된다.
Hive Server:
하이브에 쿼리하는 가장 앞 단의 서버로서 JDBC나 ODBC로부터 쿼리를 받아 드라이버에 전달한다. 하이브 서버를 통해 여러 권한 체크나 접근성을 검증할 수 있다.
Driver:
쿼리를 입력받고 해석한 뒤 작업을 처리한다. 하이브의 엔진으로서 하이브 sql의 연산 방식을 계산하고 여러 엔진들과 연동하는 역할을 담당한다. 사용자 세션을 구현하고 JDBC/ODBC 인터페이서 API를 제공한다.
Compiler:
메타스토어를 참고하여 쿼리 구문을 분석하고 실행 계획을 생성한다.
Execution Engine:
컴파일러에 의해 생성된 실행 계획을 실행한다. 맵리듀스를 실행시킨다.
LLAP(Long Live and Process):
짧은 대기 시간 분석 처리. 하이브 쿼리의 performance를 올려준다. 쿼리의 메모리 내 키싱을 수행할 수 있다.
장점
단점
사용사례

<https://wikidocs.net/23282>
<https://m.blog.naver.com/PostView.nhn?blogId=kbh3983&logNo=220971216326&proxyReferer=https%3A%2F%2Fwww.google.com%2F>
Apache Tez는 하이브와 같이 데이터를 많이 사용하는 애플리케이션을 큰 규모에서도 훨씬 더 효율적으로 실행할 수 있게 하는 프레임워크이다.
HBase
특징
HDFS 위에서 동작하는 하둡 플랫폼을 위한 비관계형 분산 데이터 베이스이다.
선형 확장성이 있다.
읽기와 쓰기의 일관성을 제공한다.
하둡과 연계하여 source가 되기도 하고 destination이 되기도 한다.
클러스터를 통한 데이터의 복제를 제공한다.
HDFS의 입력과 출력을 사용할 수 있다. 기본적으로 Java API를 통해 접근할 수 있지만 REST, Avro, Thrift 게이트웨이를 통한 접근도 가능하다.
HBase의 기본 단위는 컬럼이고, 컬럼들이 모여서 컬럼패밀리를 구성하고, 이 컬럼패밀리가 모여서 테이블을 구성한다.
Distributed(컬럼들은 쉽게 분산할 수 있다), Sparse(모든 필드에 값을 채울 필요가 없다), Column-Oriented(RDBMS는 로우 단위로 데이터를 저장하지만 HBase는 sparse하기 때문에 컬럼 단위로 한다), Versioned(하나의 row key에 여러 row가 저장될 수 있으므로 이 때 timestamp가 version이 된다), Non-Relational의 특징을 갖고 있다.
Region은 HBase에서 수평 확장(Scale-in/out)의 기본 단위다.
클라이언트는 마스터와 통신하지 않고 리전 서버와 통신하는 것으로 읽기/쓰기 작업을 할 수 있다.
주키퍼는 자체 가용성을 위해 3대나 5대로 구성한다.
각 리전서버는 ephemeral 노드로 등록이 되어서 리전 서버에 문제가 생기면 즉시 클러스터에서 제외된다.
MemStore가 컬럼패밀리 단위로 연산을 하기 때문에 HFile도 컬럼패밀리당 HFile을 생성한다.
데이터를 효율적으로 찾기 위해 multi-layerd index를 사용한다.
Bloom Filter를 제공한다.
Bloom Filter: 공간 효율적인 probabilistic data structure로 구성요소가 집합의 구성원인지 점검하는데 사용한다. HBase에서는 HFile 안에 row와 column이 존재하는지 검사하기 위한 용도로 사용한다.
Row는 RowKey와 Column으로 구성되는데 RowKey를 기준으로 알파벳 오름차순으로 정렬되어 저장된다.
구조
Master Server:
region을 region server에 할당하고 주키퍼를 이용해서 클러스터의 모든 리전 서버들을 모니터링한다.
region들의 로드 밸런싱을 수행한다. 스키마의 변화나 메타데이터의 연산을 책임진다.
Regions Server:
HDFS 데이터 노드 위에서 실행된다.
클라이언트와 통신을 하고 데이터 관련 연산을 한다.
내부 region의 읽기와 쓰기 요청을 관리한다.
클라이언트가 region에 통신하려면 주키퍼를 통해야한다.
WAL(WriteAheadLog) - 데이터는 하드디스크에 저장되기 전에 WAL에 먼저 저장된다. 데이터 저장 실패를 복구하기 위해 사용된다. WAL에 쌓인 데이터는 MemStore로 가고 이 때 클라이언트에 ack가 리턴된다.
BlockCache - 읽기 캐시로, 자주 접근하는 데이터는 메모리에 저장해서 읽기 성능을 높인다.
MemStore - 쓰기 캐시로, 아직 디스크에 기록되지 않은 데이터들이 저장된다. 각 리전의 컬럼 패밀리당 하나의 MemStore가 있다. Key-Value 형태로 정렬해서 HFile에 저장한다.
장점
RDBMS와 비교했을 때
고정 컬럼 스키마의 개념이 없다.
Regioin을 추가하면 수평적으로 확장성이 있어 큰 테이블에 적합하다.
Transaction이 존재하지 않는다.
덜 구조화된 데이터에 적합하다.
단일로우 트랜잭션을 보장한다.
단점
특정 region 서버에 특정 table의 region이 집중되기 쉬워 성능 저하로 이루어질 수 있다.
적절한 세팅을 위한 조건자료가 있으니 클러스터 규모나 기본 스펙 차이가 있어 적용이 힘들 수 있다.
사용사례
참고 HBase
<https://www.joinc.co.kr/w/man/12/hadoop/hbase/about>
특징
하둡 클러스터를 관리하는 웹 기반 관리 툴이다.
하둡 클러스터의 상태를 모니터링해서 대쉬보드에 보여준다.
암바리를 이용해서 서비스를 시작이나 중지 시킬 수 있고 클러스터에 호스트를 추가할 수 있고 서비스 설정을 업데이트 할 수 있다.
Kerberos 기반의 하둡 클러스터를 설치함으로써 authentication, authorization, auditing 등을 제공한다.
호스트에 하둡 서비스를 설치하는 것을 도와준다.
각 호스트는 암바리 에이전트의 복사본을 갖고 있어서 암바리 서버의 통제를 받을 수 있다.
아파치 애플리케이션에 단순히 뷰를 추가함으로써 기능성을 확장할 수 있다.
active directory에서 LDAP과 sync할 수 있다.
써드파티 업체들이 쉽게 암바리에 기능을 추가할 수 있도록 stack이나 view의 기능을 제공한다.
구조
암바리 서버: 관리하는 모든 동작들이 들어오는 곳이다. ambari-server.py라는 파이썬 코드에 의해 동작한다.
암바리 에이전트: 암바리로 관리하고 싶은 모든 노드들에 있다. 하트비트를 마스터로 보낸다. 이 에이전트를 통해서 서버는 여러 작업들을 한다.
암바리 스택: 암바리가 제공하는 설치/배포 기능에 다른 eco들도 쉽게 추가할 수 있도록 한다.
암바리 뷰: 새로 개발된 기능의 UI를 쉽게 추가할 수 있도록 API를 지원한다. 암바리 컨테이너 안에 넣을 수 있는 애플리케이션과 같은 것이다. 자바로 쓰여있는 server-side resource는 외부 시스템과 integrate할 수 있다. HTML, JavaScript와 같은 client-side assets는 암바리 웹에서 보여지는 것을 제공한다.
장점
하둡 클러스터를 설치, 설정, 관리하기 쉽다.
보안이나 애플리케이션 관리를 중앙화한다.
단점
사용사례
Zookeeper
특징
분산 코디네이션 서비스 시스템으로서 분산 시스템 내에서 중요한 상태 정보나 설정 정보등을 유지한다.
분산 코디네이션 시스템을 제대로 작성하지 못할 경우 SPOF가 생기거나 race condition이 생길 수 있다.
분산 시스템을 코디네이션 하는 용도이기 때문에 데이터 접근이 빨라야 하고 장애에 대한 대응 능력이 있어야 한다.
따라서 자체적으로 클러스터링을 제공하며 장애가 일어나도 데이터 유실 없이 fail over/fail back이 가능하다.
디렉토리 구조 기반으로 znode라는 데이터 저장 객체를 제공한다.
Configuration Management: 클러스터의 설정 정보를 최신으로 유지한다.
Cluster Management: 클러스터 내에 서버의 변화가 생겼을 때 다른 서버에서도 알 수 있도록 한다.
Leader Selection: 대표 노드를 고른다. 복제된 여러 노드 중 연산이 일어날 노드를 선택한다.
Locking and Synchronization System: Data condition을 예방한다.
특정 서버에 쓰기 동작을 할 경우 클라이언트가 서버에 접속해서 데이터를 업데이트하고 그 서버는 주키퍼 서버에 업데이트 내용을 알린다. 그러면 그 leader 서버(주키퍼 서버)는 broadcast형식으로 follower 주키퍼 서버들에게 보내서 전체 서버 데이터들이 일관된 상태로 유지되도록 한다.
주키퍼 클라이언트가 특정 노드에 와치를 걸어 놓으면 해당 노드가 변경 됐을 때 클라이언트로 callback호출을 날려주고 watcher는 삭제된다.
하나의 서버만 서비스를 수행하지 않고 알맞게 분산하여 각각의 클라이언트들에게 부하가 분산되도록 한다.
하나의 서버에서 처리된 결과가 다른 서버들에 동기화된다.
액티브 서버가 무너질 경우 스탠바이 서버가 액티브 서버로 바뀌어 failover/failback을 한다.
각각 서버들의 환경설정을 주키퍼 자체적으로 관리한다.
앙상블 안의 주키퍼 서버들은 조율된 상태이며 항상 같은 데이터를 갖고 있는다.
클라이언트는 앙상블의 어떤 서버에 접근해서 데이터를 읽거나 업데이트한다.
Leader가 아닌 follower 서버에 write작업이 일어나면 그 follower 서버는 leader 서버에게 업데이트 된 내용을 알려주고 그 leader 서버는 앙상블 내의 모든 follower 서버들에게 broadcast한다.
구조
각각 클라이언트를 갖고 있는 서버들을 묶어서 관리하는데 그중에서 리더 서버가 하나 있다.
앙상블(Ensemble): 여러 주키퍼 서버로 이루어졌다.
Quorum(쿼럼): 앙상블 데이터의 불일치를 방지한다.
앙상블을 이루고 있는 서버들 중에서 과반수 이상의 그룹을 묶은 뒤 쿼럼이라 한다.
예상치 못한 장애가 발생해도 시스템의 일관성을 유지하기 위함이다.
쿼럼이 과반수 이상이 아닐 때는 쿼럼의 서버들이 다운돼도 나머지들 중에서 또 쿼럼을 만들 수 있기 때문에 주키퍼가 유지된다. 유지되면 안되는데.
쿼럼이 과반수 이상일 때는 쿼럼의 서버들이 모두 다운되면 나머지들은 과반수 이하이므로 그것들로 쿼럼을 구성할 수 없기 때문에 주키퍼를 이용불가 상태로 만들어준다.
Znode: 분산 데이터 시스템.
Znode의 stat 구조에는 znode의 메타데이터가 있다.
version number: 모든 znode는 버전 넘버가 있어서 업데이트 될 때마다 이 값도 업데이트 된다.
ACL(Action Control List): 권한 획득 메커니즘이다. 이걸 통해서 노드에 접근할 수 있다.
Timestamp: Znode가 만들어진 시간과 업데이트 된 시간이 기록된다.
Data length: 데이터의 크기이다.
Znode는 세 가지 종류가 있다. Persistence znode, Ephemeral znode(leader selection에 쓰임), Sequential znode(lock에 쓰임).
장점
개발자가 코디네이션 로직보다는 비즈니스 핵심 로직에 집중하게끔 도와준다.
단점
사용사례
단순히 디렉토리 형태의 데이터 저장소이지만 다양한 시나리오에 사용될 수 있다.
와쳐와 sequence node를 이용하면 큐를 구현할 수 있다.
분산 서버가 공유 자원을 접근하려고 했을 때 특정 작업에 lock을 걸고 작업을 할 수 있는 기능을 구현할 수 있다.
Ephemeral node는 주키퍼 클라이언틀가 살아있을 때만 유효하므로 클러스터 서버들이 ephemeral node를 갖도록 하면 클러스터 내의 살아있는 서버들의 리스트를 갖고 있을 수 있다. 이와 비슷하게 leader 서버가 죽으면 다른 leader 서버를 선출하는 로직을 구현할 수도 있다.
<https://engkimbs.tistory.com/660>
Hive
특징
하둡에서 동작하는 데이터 웨어하우징 프레임워크로서 대용량 데이터 집합들을 모델링하고 프로세싱한다.
HiveQL이라고 불리는 언어를 제공하며 맵리듀스의 모든 기능을 지원한다.
맵리듀스의 상위 언어인데 피그와 다르게 절차적 언어를 사용하지 않고 SQL과 같은 쿼리를 날려서 맵리듀스를 동작시킨다. 정형화된 데이터만 처리할 수 있다.(하이브나 피그 없으면 맵리듀스 사용 못하는건가?)
HDFS의 데이터에 대해서 Meta Store에 저장된 스키마를 기준으로 데이터를 MR, Spark등의 기타 분산 엔진등을 통해 처리하고 이를 사용자에게 정형화된 결과로 제공하는 툴이다.
UI로 드라이버에 쿼리를 보낸다. 드라이버는 컴파일러에게 플랜을 요청한다. 컴파일러는 메타스토어에서 메타데이터를 불러온 뒤 플랜을 짜서 드라이버에 보낸다. 드라이버는 받은 플랜을 엑시큐션 엔진에 보낸다. execution engine은 잡을 하둡의 리소스매니저로 보낸다. 리소스매니저는 잡을 완료해서 execution engine으로 보낸다...?
사용자가 하이브웹이나 커맨드라인을 통해서 쿼리를 날린다. 드라이버는 컴파일러에게 쿼리 플랜을 요청하면 컴파일러는 쿼리 플랜을 작성한다. 컴파일러는 메타스토어로부터 쿼리를 처리하는데 필요한 메타정보를 받는다. 컴파일러는 쿼리 플랜을 작성해서 다시 드라이버에게 전달한다. 드라이버는 execution engine에게 쿼리 플랜을 전달한다. execution engine은 네임노드에 있는 잡트래커에게 잡을 전달하고 잡트래커는 태스크트래커에 잡을 임명한다.execution engine은 맵리듀스의 결과를 데이터노드로부터 받고 드라이버에게 그 결과들을 전달한다. 드라이버는 하이브 인터페이스에게 결과들을 전달한다.
기본적으로는 메타데이터를 내장된 아파치 Derby 데이터베이스에 저장하지만 다른 데이터베이스를 사용할 수도 있다.
Schema on Read이다. Table에 insert할 때 테이블 속성과 달라도 에러를 내지 않는다. 스키마온리드이기 때문에 테이블 스키마를 잘 생성해야 데이터를 의도에 맞게 read할 수 있다. 스키마온롸이트는 읽기가 빠르고 스키마온리드는 로드가 빠르다.
구조
하이브의 클라이언트는 CLI, Hive Server, Web Interface로 구성된다.
UI:
CLI, Beeline, JDBC 등.
Metastore:
하이브가 구동될 때 필요한 테이블의 스키마 구조나 다양한 설정값들이 저장된다.
Hive Server:
하이브에 쿼리하는 가장 앞 단의 서버로서 JDBC나 ODBC로부터 쿼리를 받아 드라이버에 전달한다. 하이브 서버를 통해 여러 권한 체크나 접근성을 검증할 수 있다.
Driver:
쿼리를 입력받고 해석한 뒤 작업을 처리한다. 하이브의 엔진으로서 하이브 sql의 연산 방식을 계산하고 여러 엔진들과 연동하는 역할을 담당한다. 사용자 세션을 구현하고 JDBC/ODBC 인터페이서 API를 제공한다.
Compiler:
메타스토어를 참고하여 쿼리 구문을 분석하고 실행 계획을 생성한다.
Execution Engine:
컴파일러에 의해 생성된 실행 계획을 실행한다. 맵리듀스를 실행시킨다.
LLAP(Long Live and Process):
짧은 대기 시간 분석 처리. 하이브 쿼리의 performance를 올려준다. 쿼리의 메모리 내 키싱을 수행할 수 있다.
장점
단점
사용사례
<https://wikidocs.net/23282>
<https://m.blog.naver.com/PostView.nhn?blogId=kbh3983&logNo=220971216326&proxyReferer=https%3A%2F%2Fwww.google.com%2F>
Apache Tez는 하이브와 같이 데이터를 많이 사용하는 애플리케이션을 큰 규모에서도 훨씬 더 효율적으로 실행할 수 있게 하는 프레임워크이다.
HBase
특징
HDFS 위에서 동작하는 하둡 플랫폼을 위한 비관계형 분산 데이터 베이스이다.
선형 확장성이 있다.
읽기와 쓰기의 일관성을 제공한다.
하둡과 연계하여 source가 되기도 하고 destination이 되기도 한다.
클러스터를 통한 데이터의 복제를 제공한다.
HDFS의 입력과 출력을 사용할 수 있다. 기본적으로 Java API를 통해 접근할 수 있지만 REST, Avro, Thrift 게이트웨이를 통한 접근도 가능하다.
HBase의 기본 단위는 컬럼이고, 컬럼들이 모여서 컬럼패밀리를 구성하고, 이 컬럼패밀리가 모여서 테이블을 구성한다.
Distributed(컬럼들은 쉽게 분산할 수 있다), Sparse(모든 필드에 값을 채울 필요가 없다), Column-Oriented(RDBMS는 로우 단위로 데이터를 저장하지만 HBase는 sparse하기 때문에 컬럼 단위로 한다), Versioned(하나의 row key에 여러 row가 저장될 수 있으므로 이 때 timestamp가 version이 된다), Non-Relational의 특징을 갖고 있다.
Region은 HBase에서 수평 확장(Scale-in/out)의 기본 단위다.
클라이언트는 마스터와 통신하지 않고 리전 서버와 통신하는 것으로 읽기/쓰기 작업을 할 수 있다.
주키퍼는 자체 가용성을 위해 3대나 5대로 구성한다.
각 리전서버는 ephemeral 노드로 등록이 되어서 리전 서버에 문제가 생기면 즉시 클러스터에서 제외된다.
MemStore가 컬럼패밀리 단위로 연산을 하기 때문에 HFile도 컬럼패밀리당 HFile을 생성한다.
데이터를 효율적으로 찾기 위해 multi-layerd index를 사용한다.
Bloom Filter를 제공한다.
Bloom Filter: 공간 효율적인 probabilistic data structure로 구성요소가 집합의 구성원인지 점검하는데 사용한다. HBase에서는 HFile 안에 row와 column이 존재하는지 검사하기 위한 용도로 사용한다.
Row는 RowKey와 Column으로 구성되는데 RowKey를 기준으로 알파벳 오름차순으로 정렬되어 저장된다.
구조
Master Server:
region을 region server에 할당하고 주키퍼를 이용해서 클러스터의 모든 리전 서버들을 모니터링한다.
region들의 로드 밸런싱을 수행한다. 스키마의 변화나 메타데이터의 연산을 책임진다.
Regions Server:
HDFS 데이터 노드 위에서 실행된다.
클라이언트와 통신을 하고 데이터 관련 연산을 한다.
내부 region의 읽기와 쓰기 요청을 관리한다.
클라이언트가 region에 통신하려면 주키퍼를 통해야한다.
WAL(WriteAheadLog) - 데이터는 하드디스크에 저장되기 전에 WAL에 먼저 저장된다. 데이터 저장 실패를 복구하기 위해 사용된다. WAL에 쌓인 데이터는 MemStore로 가고 이 때 클라이언트에 ack가 리턴된다.
BlockCache - 읽기 캐시로, 자주 접근하는 데이터는 메모리에 저장해서 읽기 성능을 높인다.
MemStore - 쓰기 캐시로, 아직 디스크에 기록되지 않은 데이터들이 저장된다. 각 리전의 컬럼 패밀리당 하나의 MemStore가 있다. Key-Value 형태로 정렬해서 HFile에 저장한다.
장점
RDBMS와 비교했을 때
고정 컬럼 스키마의 개념이 없다.
Regioin을 추가하면 수평적으로 확장성이 있어 큰 테이블에 적합하다.
Transaction이 존재하지 않는다.
덜 구조화된 데이터에 적합하다.
단일로우 트랜잭션을 보장한다.
단점
특정 region 서버에 특정 table의 region이 집중되기 쉬워 성능 저하로 이루어질 수 있다.
적절한 세팅을 위한 조건자료가 있으니 클러스터 규모나 기본 스펙 차이가 있어 적용이 힘들 수 있다.
사용사례
참고 HBase
<https://www.joinc.co.kr/w/man/12/hadoop/hbase/about>

댓글
댓글 쓰기