오픈소스 프레임워크 정리(ElasticSearch, Docker, Kerberos, Ansible)
ElasticSearch
특징
정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 루씬 기반의 분산형 오픈 소스 검색 및 분석 엔진이다.
자바로 개발되었다.
로그스태시라는 데이터 수집 및 로그 파싱 엔진과, 키바나라는 분석 및 시각화 플랫폼과 함께 개발되었다.
이 세 가지를 ELK 스택으로 부른다.
로그스태시로부터 받은 데이터를 검색 및 집계를 해서 필요한 관심 있는 정보를 획득한다.
클러스터는 하나 이상의 노드들로 이루어진 집합니다. 서로 다른 클러스터는 데이터를 교환할 수 없는 독립적인 시스템으로 유지된다. 여러 서버가 한 클러스터를 구성할 수도 있고 한 서버에 여러 클러스터가 존재할 수도 있다.
노드는 엘라스틱서치를 구성하는 하나의 단위 프로세스이다. Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
Master-eligible node: 마스터로 선택할 수 있는 노드이다. 마스터는 인덱스 생성/삭제, 클러스터 노드들의 추적/관리, 데이터 입력 시 할당될 샤드 선택 등을 한다.
Data node: 데이터 CRUD 작업이 관련된 노드이다. 자원을 많이 소비하므로 모니터링이 필요하다.
Ingest node: 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할이다.
Coordination only node: 로드 밸런서와 비슷한 역할을 한다.
샤딩: 데이터를 분산해서 저장하는 방법
레플리카: 또 다른 형태의 샤드라 볼 수 있다. 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드를 복제한다.
테이블과 스키마 대신 문서 구조로 된 데이터를 사용한다.
Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없고 자동으로 인덱싱해준다.
데이터 CRUD 작업은 HTTP Restful API를 통해 수행된다.
샤드를 통해 규모가 수평적으로 scale out할 수 있다.
multi-tenancy: 하나의 엘라스틱서버에 여러 인덱스를 저장하고 여러 인덱스의 데이터를 하나의 쿼리로 검색할 수 있다.
Thrift 플러그인이나 Jetty 플러그인을 사용하면 전송 프로토콜을 변경할 수 있다.
BigDesk나 Head를 설치하면 엘라스틱서치 모니터링 기능을 사용할 수 있게 된다.
키에 따라 여러 샤드가 구성되는 방식으로 데이터를 분산한다.
마스터 노드가 다운되면 자동으로 클러스터 내 다른 노드가 마스터가 된다.
샤드는 데이터 검색을 위해 구분되는 최소 단위이다.
색인된 데이터는 여러 개의 샤드로 분할되어 저장된다.
최초샤드(Primary Shard)에 데이터가 색인되면 동일한 수 만큼 레플리카를 생성한다. 최초 샤드가 유실되는 경우 레플리카를 프라이머리 샤드로 승격한다. 프라이머리 샤드와 레플리카는 서로 다른 노드에 저장한다.
엘리스틱서치의 검색 방법은 크게 쿼리와 필터로 나뉜다.

<https://d2.naver.com/helloworld/273788>
구조
Document: 엘라스틱서치 데이터가 저장되는 최소 단위이다. 인덱싱 될 수 있는 정보의 기본 단위이다. JSON으로 표현된다.
Type: 여러 개의 다큐먼트는 하나의 type을 이룬다.
Index: 여러 개의 타입은 하나의 인덱스로 구성된다.
샤드: 인덱스를 샤드라 불리는 여러 개의 조각으로 나눌 수 있다.
레플리카: 샤드에 대한 한 개 이상의 복사본이다. HA 제공한다. 검색이 모든 레플리카에서 병렬적으로 실행될 수 있게 해주기 때문에 검색의 볼륨 스케일 업을 해줄 수 있다.
장점
루씬 기반으로 구축되기 대문에 전체 텍스트 검색에 뛰어나고, 문서가 색인될 때부터 검색 가능해질 때까지의 대기 시간이 아주 짧아서 빠르다.
엘라스틱서치에 저장된 문서는 샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산되며 하드웨어 장애에 사용되는 등 본질상 분산적이다.
데이터 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 강력한 기본 기능이 다수 탑재되어 있다.
단점
사용사례
애플리케이션 검색, 웹사이트 검색, 엔터프라이즈 검색, 로깅과 로그 분석 등에 쓰인다.
Docker
특징
컨테이너 기반의 오픈소스 가상화 플랫폼이다.
기존의 os 가상화는 host os 위에 hypervisor 위에 guest os 전체를 가상화하는 방식이었다.
컨테이너는 대신 프로세스를 격리함으로써 서로 영향을 미치지 않고 독립적으로 실행되어 가벼운 가상화 머신을 사용하는 느낌을 준다.
이미지는 컨테이너를 실행하기 위한 모든 정보가 있기 때문에 새로운 서버가 추가되더라도, 다른 운영체제라고 하더라도 미리 만들어 놓은 이미지를 다운 받고 컨테이너를 생성만 하면 된다.
도커 파일은 서버 운영 기록을 코드화 해놓은 것이고, 도커 이미지는 도커 파일에 실행 시점을 더한 것을 의미한다고 볼 수 있다.
구조
이미지: 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않는다.
장점
서버 코드화의 장점들:
다른 이가 만든 서버를 소프트웨어 사용하듯 가져다 쓸 수 있다.
여러 대에 배포할 수 있는 확장성이 있다.
다른 사람에게 서버 운영 기록을 인계할 때 편하다.
비저장성 때문에 persistency를 갖지 않고, 오히려 이게 장점이 될 수 있는게 컨테이너 내용을 일관되게 만들 수 있다는 것이다.
가상머신보다 훨씬 더 적은 메모리를 사용한다.
단점
Persistency를 갖고 있지 않다. 새 컨테이너 인스턴스를 시작하면 기존 컨테이너와 연결된 상태 정보는 없어진다.
반면 가상머신은 세션에 대한 persistency를 갖고 있다. 자체 파일 시스템을 갖고 있기 때문이다.
사용사례
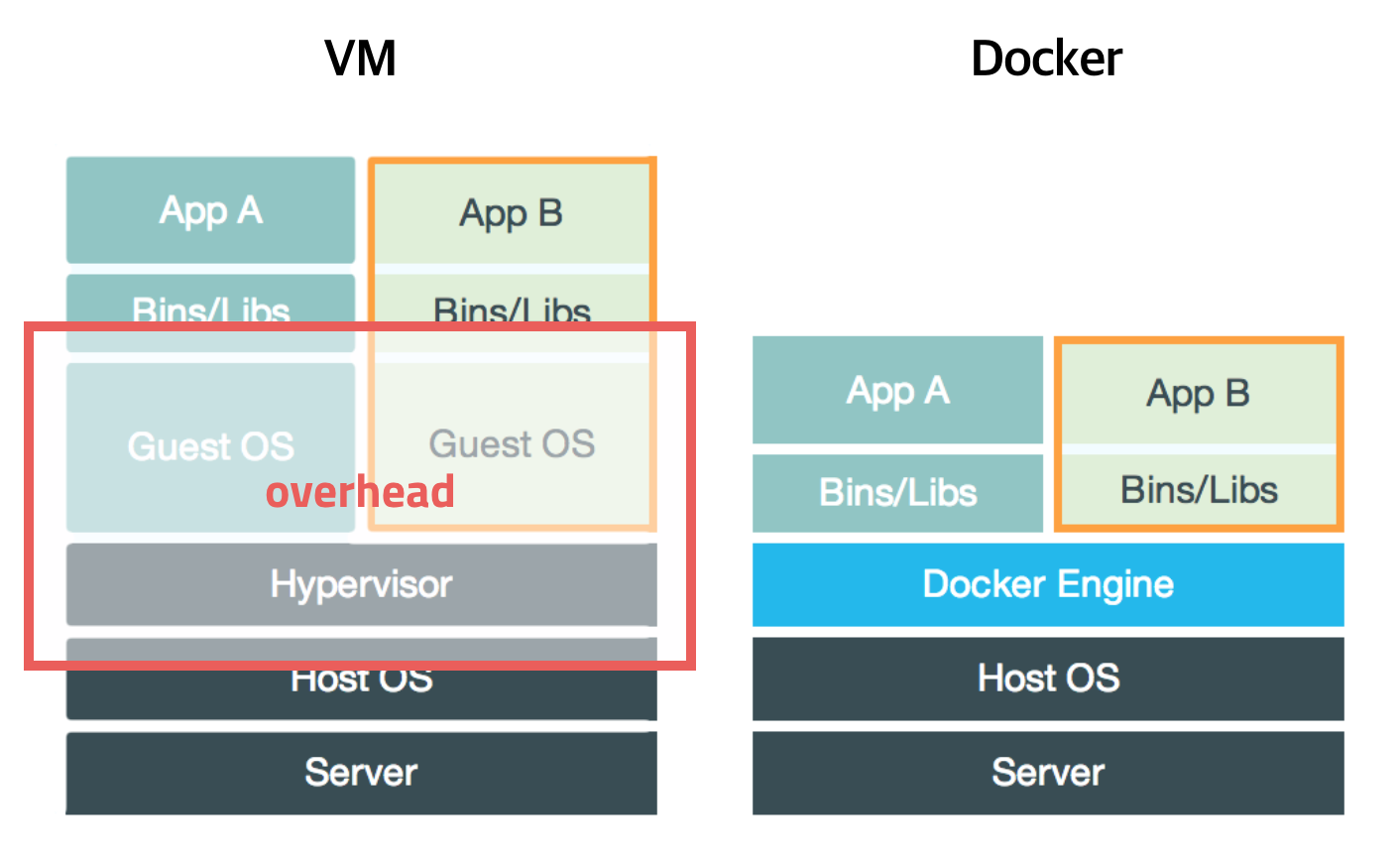
<https://subicura.com/2017/01/19/docker-guide-for-beginners-1.html>
Kerberos
동일한 계정으로 여러가지 서비스를 받게 해준다.(SSO)
미리 공유된 비밀키를 이용해서 네트워크를 통해 패스워드가 전송되지 않는 end-to-end 암호화를 지원한다.
AS(Authentication Server = KDC = Key Distrubution Center)에는 모든 사용자의 패스워드가 있다.
TGS(Ticket Granting Service)는 AS에서 인증받은 사용자들에 대해 각 필요한 서비스의 티켓을 발행해준다.
TGT(Ticket Granting Ticket)은 AS에서 주는 티켓으로서 로그인 세션마다 한 번만 발급받고 서버에서 인증을 받았다고 증명을 해준다.
SGT(Service Granting Ticket)은 TGS에서 주는 티켓으로서 TGT를 보고 발행해주는 1회용 티켓이다.
SSO의 공통적인 문제점인 단일실패지점(Single Point of Failure)의 위험성을 갖고 있다.
대칭키의 공통적인 문제점인 패스워드 탈취의 위험성이 있다.
KDC의 공통적인 문제점인 요청이 많아질수록 부하가 커지는 단점이 있다.
Ansible
여러 개의 서버를 효율적으로 관리하기 위한 환경 구성 자동화 도구이다.
Infrastructure as a Code의 개념으로 인프라 상태를 코드로 선언하고 이를 모든 서버에 배포함으로써 특정 환경을 동일하게 유지한다.
플레이북이라는 곳에 서버 등의 구성을 선언해 놓으면 필요할 때 마다 자동으로 실행시킬 수 있다.
인벤토리 / 플레이북 / 모듈로 이루어져 있다.
인벤토리: 앤서블에 의해 제어될 대상을 정의한다. hosts.ini파일에 정의한다. 여러 서버들의 접속 정보를 정의한다.
플레이북: 인벤토리 파일에서 정의한 대상들이 무엇을 수행할 것인지 정의하는 역할을 한다. yaml 포맷으로 설정한다. 인벤토리와의 조합으로 같이 사용된다.
모듈: 플레이북에서 task가 어떻게 수행될지를 정의하는 요소이다.
애드혹: /etc/ansible/hosts에 나열된 서버들에 원격지 명령을 보낸다.
Ansible Tower
오픈소스인 앤서블에 GUI 콘솔, 워크플로우, 인증환경, 사용자관리, 작업 결과 관리, 모니터링 등의 실 업무를 위한 기능을 추가하여 기업제품으로 만든 것이다.
앤서블에 대한 이해가 필요하다.
특징
정형 및 비정형 데이터 등 모든 유형의 데이터를 위한 루씬 기반의 분산형 오픈 소스 검색 및 분석 엔진이다.
자바로 개발되었다.
로그스태시라는 데이터 수집 및 로그 파싱 엔진과, 키바나라는 분석 및 시각화 플랫폼과 함께 개발되었다.
이 세 가지를 ELK 스택으로 부른다.
로그스태시로부터 받은 데이터를 검색 및 집계를 해서 필요한 관심 있는 정보를 획득한다.
클러스터는 하나 이상의 노드들로 이루어진 집합니다. 서로 다른 클러스터는 데이터를 교환할 수 없는 독립적인 시스템으로 유지된다. 여러 서버가 한 클러스터를 구성할 수도 있고 한 서버에 여러 클러스터가 존재할 수도 있다.
노드는 엘라스틱서치를 구성하는 하나의 단위 프로세스이다. Master-eligible, Data, Ingest, Tribe 노드로 구분할 수 있다.
Master-eligible node: 마스터로 선택할 수 있는 노드이다. 마스터는 인덱스 생성/삭제, 클러스터 노드들의 추적/관리, 데이터 입력 시 할당될 샤드 선택 등을 한다.
Data node: 데이터 CRUD 작업이 관련된 노드이다. 자원을 많이 소비하므로 모니터링이 필요하다.
Ingest node: 데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할이다.
Coordination only node: 로드 밸런서와 비슷한 역할을 한다.
샤딩: 데이터를 분산해서 저장하는 방법
레플리카: 또 다른 형태의 샤드라 볼 수 있다. 노드를 손실했을 경우 데이터의 신뢰성을 위해 샤드를 복제한다.
테이블과 스키마 대신 문서 구조로 된 데이터를 사용한다.
Json 문서를 통해 데이터 검색을 수행하므로 스키마 개념이 없고 자동으로 인덱싱해준다.
데이터 CRUD 작업은 HTTP Restful API를 통해 수행된다.
샤드를 통해 규모가 수평적으로 scale out할 수 있다.
multi-tenancy: 하나의 엘라스틱서버에 여러 인덱스를 저장하고 여러 인덱스의 데이터를 하나의 쿼리로 검색할 수 있다.
Thrift 플러그인이나 Jetty 플러그인을 사용하면 전송 프로토콜을 변경할 수 있다.
BigDesk나 Head를 설치하면 엘라스틱서치 모니터링 기능을 사용할 수 있게 된다.
키에 따라 여러 샤드가 구성되는 방식으로 데이터를 분산한다.
마스터 노드가 다운되면 자동으로 클러스터 내 다른 노드가 마스터가 된다.
샤드는 데이터 검색을 위해 구분되는 최소 단위이다.
색인된 데이터는 여러 개의 샤드로 분할되어 저장된다.
최초샤드(Primary Shard)에 데이터가 색인되면 동일한 수 만큼 레플리카를 생성한다. 최초 샤드가 유실되는 경우 레플리카를 프라이머리 샤드로 승격한다. 프라이머리 샤드와 레플리카는 서로 다른 노드에 저장한다.
엘리스틱서치의 검색 방법은 크게 쿼리와 필터로 나뉜다.

<https://d2.naver.com/helloworld/273788>
구조
Document: 엘라스틱서치 데이터가 저장되는 최소 단위이다. 인덱싱 될 수 있는 정보의 기본 단위이다. JSON으로 표현된다.
Type: 여러 개의 다큐먼트는 하나의 type을 이룬다.
Index: 여러 개의 타입은 하나의 인덱스로 구성된다.
샤드: 인덱스를 샤드라 불리는 여러 개의 조각으로 나눌 수 있다.
레플리카: 샤드에 대한 한 개 이상의 복사본이다. HA 제공한다. 검색이 모든 레플리카에서 병렬적으로 실행될 수 있게 해주기 때문에 검색의 볼륨 스케일 업을 해줄 수 있다.
장점
루씬 기반으로 구축되기 대문에 전체 텍스트 검색에 뛰어나고, 문서가 색인될 때부터 검색 가능해질 때까지의 대기 시간이 아주 짧아서 빠르다.
엘라스틱서치에 저장된 문서는 샤드라고 하는 여러 다른 컨테이너에 걸쳐 분산되며 하드웨어 장애에 사용되는 등 본질상 분산적이다.
데이터 롤업, 인덱스 수명 주기 관리 등과 같이 데이터를 훨씬 더 효율적으로 저장하고 검색할 수 있게 해주는 강력한 기본 기능이 다수 탑재되어 있다.
단점
사용사례
애플리케이션 검색, 웹사이트 검색, 엔터프라이즈 검색, 로깅과 로그 분석 등에 쓰인다.
Docker
특징
컨테이너 기반의 오픈소스 가상화 플랫폼이다.
기존의 os 가상화는 host os 위에 hypervisor 위에 guest os 전체를 가상화하는 방식이었다.
컨테이너는 대신 프로세스를 격리함으로써 서로 영향을 미치지 않고 독립적으로 실행되어 가벼운 가상화 머신을 사용하는 느낌을 준다.
이미지는 컨테이너를 실행하기 위한 모든 정보가 있기 때문에 새로운 서버가 추가되더라도, 다른 운영체제라고 하더라도 미리 만들어 놓은 이미지를 다운 받고 컨테이너를 생성만 하면 된다.
도커 파일은 서버 운영 기록을 코드화 해놓은 것이고, 도커 이미지는 도커 파일에 실행 시점을 더한 것을 의미한다고 볼 수 있다.
구조
이미지: 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않는다.
장점
서버 코드화의 장점들:
다른 이가 만든 서버를 소프트웨어 사용하듯 가져다 쓸 수 있다.
여러 대에 배포할 수 있는 확장성이 있다.
다른 사람에게 서버 운영 기록을 인계할 때 편하다.
비저장성 때문에 persistency를 갖지 않고, 오히려 이게 장점이 될 수 있는게 컨테이너 내용을 일관되게 만들 수 있다는 것이다.
가상머신보다 훨씬 더 적은 메모리를 사용한다.
단점
Persistency를 갖고 있지 않다. 새 컨테이너 인스턴스를 시작하면 기존 컨테이너와 연결된 상태 정보는 없어진다.
반면 가상머신은 세션에 대한 persistency를 갖고 있다. 자체 파일 시스템을 갖고 있기 때문이다.
사용사례
<https://subicura.com/2017/01/19/docker-guide-for-beginners-1.html>
Kerberos
동일한 계정으로 여러가지 서비스를 받게 해준다.(SSO)
미리 공유된 비밀키를 이용해서 네트워크를 통해 패스워드가 전송되지 않는 end-to-end 암호화를 지원한다.
AS(Authentication Server = KDC = Key Distrubution Center)에는 모든 사용자의 패스워드가 있다.
TGS(Ticket Granting Service)는 AS에서 인증받은 사용자들에 대해 각 필요한 서비스의 티켓을 발행해준다.
TGT(Ticket Granting Ticket)은 AS에서 주는 티켓으로서 로그인 세션마다 한 번만 발급받고 서버에서 인증을 받았다고 증명을 해준다.
SGT(Service Granting Ticket)은 TGS에서 주는 티켓으로서 TGT를 보고 발행해주는 1회용 티켓이다.
SSO의 공통적인 문제점인 단일실패지점(Single Point of Failure)의 위험성을 갖고 있다.
대칭키의 공통적인 문제점인 패스워드 탈취의 위험성이 있다.
KDC의 공통적인 문제점인 요청이 많아질수록 부하가 커지는 단점이 있다.
Ansible
여러 개의 서버를 효율적으로 관리하기 위한 환경 구성 자동화 도구이다.
Infrastructure as a Code의 개념으로 인프라 상태를 코드로 선언하고 이를 모든 서버에 배포함으로써 특정 환경을 동일하게 유지한다.
플레이북이라는 곳에 서버 등의 구성을 선언해 놓으면 필요할 때 마다 자동으로 실행시킬 수 있다.
인벤토리 / 플레이북 / 모듈로 이루어져 있다.
인벤토리: 앤서블에 의해 제어될 대상을 정의한다. hosts.ini파일에 정의한다. 여러 서버들의 접속 정보를 정의한다.
플레이북: 인벤토리 파일에서 정의한 대상들이 무엇을 수행할 것인지 정의하는 역할을 한다. yaml 포맷으로 설정한다. 인벤토리와의 조합으로 같이 사용된다.
모듈: 플레이북에서 task가 어떻게 수행될지를 정의하는 요소이다.
애드혹: /etc/ansible/hosts에 나열된 서버들에 원격지 명령을 보낸다.
Ansible Tower
오픈소스인 앤서블에 GUI 콘솔, 워크플로우, 인증환경, 사용자관리, 작업 결과 관리, 모니터링 등의 실 업무를 위한 기능을 추가하여 기업제품으로 만든 것이다.
앤서블에 대한 이해가 필요하다.

댓글
댓글 쓰기